Microchip Technology Inc.
Avtor: Yann LeFaou, pomočnik direktorja v Microchipovi poslovni enoti za dotik in geste
Povpraševanje po industrijskih aplikacijah interneta stvari, ki lahko izvajajo modele strojnega učenja (ML) v lokalnih napravah in ne v oblaku, od napovednega vzdrževanja in prepoznavanja slik do oddaljenega spremljanja sredstev in nadzora dostopa, hitro narašča.
Te tako imenovane „ML na robu“ ali Edge ML namestitve poleg podpore okoljem, v katerih je treba senzorske podatke zbirati daleč od oblaka, ponujajo tudi prednosti, ki vključujejo nizko zakasnitev, sklepanje v realnem času, manjšo komunikacijsko pasovno širino, izboljšano varnost in nižje stroške. Seveda pa izvajanje Edge ML ni brez izzivov, naj gre za omejeno procesorsko moč in pomnilnik naprave, razpoložljivost ali ustvarjanje ustreznih zbirk podatkov ali dejstvo, da večina inženirjev za ugnezdene aplikacije nima znanja s področja podatkovne znanosti. Dobra novica pa je, da obstaja vse večji ekosistem strojne in programske opreme, razvojnih orodij in podpore, ki razvijalcem pomaga pri reševanju teh izzivov.


V tem članku si bomo podrobneje ogledali izzive in opredelili deset ključnih dejavnikov, ki jih morajo upoštevati razvijalci ugnezdenih aplikacij.
Predstavitev Edge ML
Strojno učenje (ML), ki je temelj umetne inteligence, uporablja algoritme za sklepanje na podlagi svežih/živih in preteklih podatkov. Doslej so se ML aplikacije izvajale tako, da se je večina obdelave podatkov izvajala v oblaku. Edge ML zmanjšuje ali odpravlja odvisnost od oblaka, saj lokalnim IoT napravam omogoča analizo podatkov, izdelavo modelov in napovedi ter ukrepanje. Poleg tega lahko naprava nenehno izboljšuje svojo učinkovitost in natančnost, in sicer samodejno in z malo ali nič človeškega posredovanja.
Edge ML lahko močno spodbudi industrijo 4.0, saj bo obdelava v realnem času na robu izboljšala učinkovitost proizvodnje, koristi pa bodo imele tudi aplikacije, ki segajo od avtomatizacije stavb do varnosti in nadzora. Zato je potencial ML na robu ogromen, kar je razvidno iz nedavne študije družbe ABI Research, ki napoveduje, da bo trg ML na robu do leta 2027 [1] presegel 5 milijard ameriških dolarjev. Medtem ko je bil ML nekoč v domeni matematične in znanstvene skupnosti, je vse bolj del inženirskega procesa in zlasti pomemben element inženiringa ugnezdenih sistemov.
Izzivi, povezani z izvajanjem Edge ML, se zato ne navezujejo toliko na vprašanje „Kje začeti?“, temveč bolj na vprašanje „Kako to narediti hitro in stroškovno učinkovito?“ Naslednjih 10 premislekov naj bi pomagalo odgovoriti na to vprašanje.
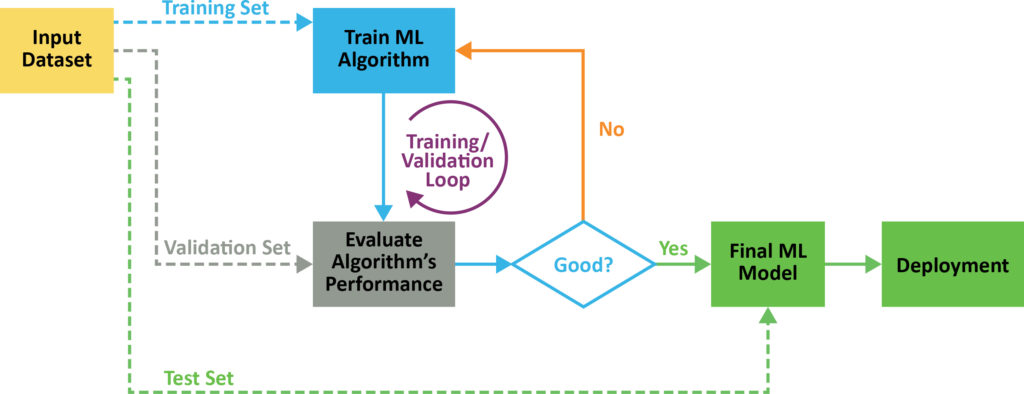
- Zajem podatkov
Do zdaj se je večina namestitev ML izvajala v zmogljivih računalnikih ali strežnikih v oblaku. Vendar pa je treba ML na robu izvajati v ugnezdeni strojni opremi, ki je omejena s prostorom in energijo. Uporaba pametnih senzorjev, ki v fazi zajemanja podatkov izvajajo določeno stopnjo predobdelave, bo močno olajšala organizacijo in analizo podatkov, saj poskrbijo za prva dva koraka v ML procesnem toku (glej sliko 1). Pametni senzor lahko ustvari eno od dveh vrst pametnih modelov; tiste, ki so usposobljeni za reševanje preproste klasifikacije, ali tiste, ki so usposobljeni za reševanje problemov, ki temeljijo na regresiji. - Vmesniki
ML modeli morajo biti uporabni, kar zahteva vmesnike med sestavnimi (programskimi) deli naprave. Kakovost teh vmesnikov bo določala, kako učinkovito bo naprava delovala in se lahko sama učila. Mejo ML modela sestavljajo vhodi in izhodi. Upoštevanje vseh vhodnih funkcij je razmeroma enostavno. Skrb za napovedi modela je manjša, zlasti v nenadzorovanem sistemu. Seveda so vmesniki povezani tudi s fizično povezavo med elementi strojne opreme. Ti so lahko tako preprosti, kot so povezave za USB ali zunanji pomnilnik, ali bolj zapleteni vmesniki, ki podpirajo povezave za video tokove in uporabniško specifične vhode. Aplikacije Edge ML so po definiciji prostorsko, energetsko in stroškovno omejene, zato je treba razmisliti o najmanjšem številu in vrsti potrebnih vmesnikov. - Ustvarjanje optimiziranih zbirk podatkov
Uporaba komercialno dostopnih zbirk podatkov (zbirka podatkov, ki so že urejeni v določenem vrstnem redu) je dober način za pospešitev Edge ML razvojnega projekta. Nabor podatkov je treba optimizirati za uporabo v skladu z namenom Edge ML naprave. Obravnavajte na primer varnostni scenarij, v katerem je treba spremljati vedenje ljudi in samodejno označevati sumljivo vedenje. Če ima lokalna nadzorna naprava vgrajen vid in zmožnost prepoznati, kaj ljudje počnejo – na primer stojijo, sedijo, hodijo, tečejo ali puščajo torbo/kovček brez nadzora – je mogoče odločitve sprejemati pri viru podatkov. Namesto da bi napravo usposobili od začetka, bi bil del vhodnega nabora podatkov nabor za usposabljanje (glej sliko 3), kot je MPII Human Pose (položaj človeka), ki vključuje približno 25.000 slik, pridobljenih iz spletnih videoposnetkov. Podatki so označeni, zato jih je mogoče uporabiti za nadzorovano strojno učenje. - Zahteve glede procesorske moči
Procesorska moč, ki je potrebna za Edge ML, se razlikuje glede na aplikacijo. Obdelava slik na primer potrebuje več procesorske moči kot aplikacija, ki temelji na zajemanju senzorja ali nadzoru vhodnih podatkov. ML modeli, nameščeni v pametnih napravah, delujejo najbolje, če so majhni in če so naloge, ki se od njih zahtevajo, preproste. Z večanjem velikosti modelov in zapletenosti nalog se eksponentno povečuje potreba po večji procesorski moči. Če ta ni izpolnjena, se bo zmanjšala zmogljivost sistema (v smislu hitrosti in/ali natančnosti). Vendar k možnosti uporabe manjših čipov za ML prispevajo izboljšave algoritmov in odprtokodnih modelov (kot je TinyML), ogrodij ML in sodobnih IDE, ki inženirjem pomagajo pri izdelavi učinkovitih modelov. - Polprevodniki / pametni senzorji
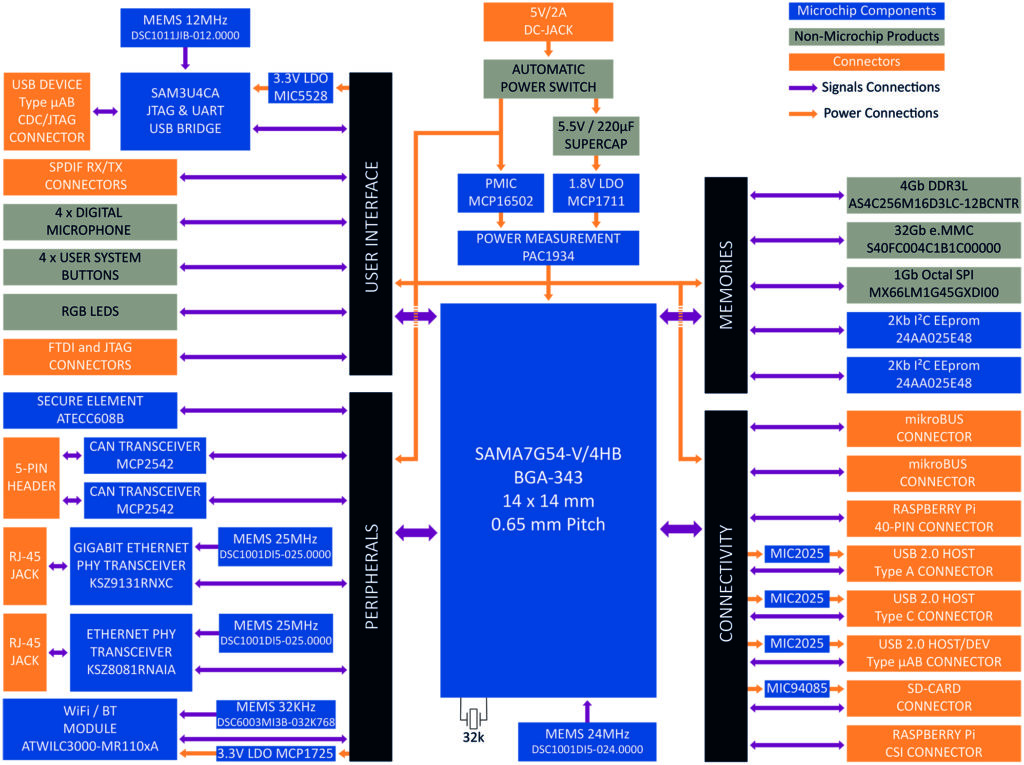
Številne Edge ML aplikacije zahtevajo obdelavo na robu za prepoznavanje slik in zvoka. MPU-ji in FPGA-ji, ki lahko podpirajo obdelavo v oblaku za takšne aplikacije, so na voljo že nekaj časa, zdaj pa je zaradi razpoložljivosti polprevodnikov z nizko porabo energije za integracijo te funkcionalnosti razvoj aplikacij na robu veliko enostavnejši. Microchipov 1 GHz SAMA7G54 (slika 2) je na primer prvi enojedrni MPU z vmesnikom za kamero MIPI CSI-2 in naprednimi zvočnimi funkcijami. Ta naprava združuje celoten slikovni in avdio podsistem, podpira do 8 milijonov slikovnih pik in 720p @ 60 fps, do štiri I2S, en oddajnik in sprejemnik SPDIF ter 4-kanalni pretvornik vzorčne frekvence zvoka. Poleg tega za napredno obdelavo na robu ni več potrebna posebna naprava. Inženirji ugotavljajo, da se napredek v polprevodniških tehnologijah in ML algoritmih združuje, tako da komercialno dostopni 16-bitni in celo 8-bitni MCU-ji postajajo možnost za učinkovito izvedbo Edge ML. Pri številnih aplikacijah je uporaba takšnih naprav z majhno močjo in v majhnem ohišju predpogoj za zagotavljanje industrijskih Edge ML sistemov, ki temeljijo na senzorjih in se napajajo z baterijami, ter so namenjeni industrijskemu IoT. - Odprtokodna orodja, modeli, ogrodja in IDE-ji
Pri vsakem razvoju bo razpoložljivost odprtokodnih orodij, modelov, ogrodij in dobro razumljivih integriranih razvojnih okolij poenostavila in pospešila načrtovanje, testiranje, izdelavo prototipov in zmanjšala tako pomemben čas za lansiranje na trg. V primeru strojnega učenja na robu je še posebej pomemben pojav „drobnega strojnega učenja“ (Tiny Machine Learning ali TinyML). Po opredelitvi fundacije tinyML je to „hitro rastoče področje tehnologij in aplikacij strojnega učenja, vključno s strojno opremo (posebna integrirana vezja), algoritmi in programsko opremo, ki lahko izvaja analizo podatkov senzorjev (video, zvočnih, IMU, biomedicinskih itd.) v napravi pri izjemno nizki porabi energije, običajno v območju mW in manj, ter tako omogoča različne primere uporabe, ki so vedno na voljo, in je usmerjena na naprave, ki delujejo na baterije.“ Zahvaljujoč TinyML gibanju se je v zadnjih letih eksponentno povečala razpoložljivost orodij in podpore, ki olajšujejo delo inženirjev ugnezdenega načrtovanja.
Dobra primera takih orodij sta Edge Impulse in SensiML™. Ta orodja, ki zagotavljajo „TinyML kot storitev“, pri kateri se lahko ML aplikacija uporablja v obsegu le nekaj kilobajtov, so popolnoma združljiva s knjižnico TensorFlow™ Lite za uvajanje modelov na mobilnih napravah, mikrokontrolerjih in drugih napravah na robu. Z izbiro takšnih orodij lahko razvijalci zagotovijo hitro klasifikacijo, regresijo in odkrivanje anomalij, poenostavijo zbiranje dejanskih senzorskih podatkov, zagotovijo obdelavo signalov v živo od surovih podatkov do nevronskih omrežij ter pospešijo testiranje in poznejšo namestitev v ciljno napravo.
- Razvojni kiti
Večja razpoložljivost razvojnih kompletov je še en dejavnik, ki prispeva k hitrejšemu izvajanju Edge ML aplikacij. Številni izdelki, ki se tržijo, temeljijo na strojni opremi in ugnezdeni programski opremi (ter gonilnikih, programskih modulih in algoritmih, ki delujejo na njih) ugnezdenih sistemskih razvojnih kompletih, ki so primerni za razvoj ML aplikacij in so na voljo pri številnih prodajalcih. Na primer, Raspberry Pi 4 Model B temelji na štirijedrnem 64-bitnem SoC Broadcom® BCM2711 Cortex®-A72 (s taktom 1,5 GHz), ima grafični procesor Broadcom VideoCore® VI in 1/2/4 GB LPDDR4 RAM ter lahko zagotovi od 13,5 do 32 GFLOPS računske zmogljivosti. Pri razvoju zasnove je vredno porabiti nekaj časa za raziskovanje delov, ki se uporabljajo v razvojnih kompletih, saj je lahko koristno, da končno aplikacijo sestavite z uporabo istega silicija. Če na primer ML aplikacija zahteva ugnezden vid, so Microchipovi FPGA PolarFire® SoC idealni za računsko intenzivno obdelavo vida na robu, saj podpirajo ločljivost do 4k z nizkimi 12,37 SERDES. - Varnost podatkov
Kar zadeva varnost, je dobra novica to, da se pri Edge ML v oblak prenaša veliko manj podatkov, kar pomeni, da je potencialna možnost za kibernetske napade bistveno manjša. Kljub temu uvedba Edge ML prinaša nove izzive, saj vse naprave na robu – ne glede na to, ali podpirajo ML ali ne – nimajo več inherentne varnosti oblaka in morajo biti neodvisno zaščitene tako, kot vse druge IoT naprave ali ugnezdeni sistemi, povezani v omrežje.
Varnostni vidiki, ki jih je treba upoštevati, vključujejo:
Kako enostavno lahko hekerji spremenijo podatke (ki se vnašajo in/ali uporabljajo za usposabljanje) ali ML model?
Kako varni so podatki? Ali je mogoče do njih dostopati pred šifriranjem? Pri tem je treba opozoriti, da je za šifriranje treba ključe hraniti na varnem (ne očitnem) mestu.
Kako varno je omrežje? Ali obstaja nevarnost, da se nepooblaščene (ali navidezno pooblaščene) naprave povežejo in povzročijo škodo?
Ali je Edge ML napravo mogoče klonirati?
Zahtevana raven varnosti je seveda odvisna od aplikacije (lahko je na primer varnostno kritična) in/ali narave „večjega sistema“, katerega del je Edge ML naprava.
- Lastne zmogljivosti
V tipični inženirski ekipi so različne stopnje razumevanja ML in AI. Odprtokodna orodja, razvojni kompleti in nabori podatkov, ki so na voljo, pomenijo, da inženirji ugnezdenih naprav ne potrebujejo poglobljenega razumevanja podatkovne znanosti ali nevronskih mrež globokega učenja. Vendar pa lahko pri uvajanju katere koli nove inženirske discipline ali metodologije (ali vlaganju v orodja) čas, porabljen za usposabljanje, dolgoročno vodi do krajšega razvojnega časa, manjšega števila zasnov in boljšega rezultata na inženirja. Številne informacije o ML na spletu v obliki učbenikov, belih knjig in spletnih seminarjev (ter dejstvo, da inženirski sejmi organizirajo seminarje in delavnice o ML) zagotavljajo številne priložnosti za izboljšanje zmogljivosti razvojne ekipe. Med bolj formalnimi tečaji je program MIT Professional Certificate Program in ML and AI, Imperial College v Londonu pa izvaja spletni tečaj, ki vključuje modul o razvoju in izpopolnjevanju ML modelov z uporabo Pythona in standardnih industrijskih orodij za merjenje in izboljšanje učinkovitosti. Nazadnje je zdaj mogoče povečati zmogljivosti inženirske ekipe z generativnimi orodji umetne inteligence, kar omogoča novincem, da kodirajo zapletene aplikacije, medtem ko bi lahko upoštevanje ML usposabljanja v primerjavi z neposrednim programiranjem privedlo tudi do krajšega časa razvoja, manj ponovnih različic in boljših rezultatov. - Podpora dobaviteljem in partnerstva z njimi
Razvoj aplikacije za napravo s podporo ML je veliko lažji s podporo dobaviteljev, ki so že dejavni na tem področju. Na primer, za ML v oblaku ima AWS priljubljen program „Machine Learning Competency Partners“. Posebej v primeru Edge ML je priporočljivo pogledati dlje od samega dobavljenega izdelka in razmisliti o morebitnih prednostih obstoječih sodelovanj dobavitelja. Podjetje Microchip je na primer vložilo veliko sredstev v vzpostavitev odnosov s partnerji, od prodajalcev senzorjev do ponudnikov orodij, da bi strankam zagotovilo dostop do vsega, od osnovnega svetovanja in usmerjanja do zagotavljanja rešitev na ključ.
Zaključek
Čeprav bi vsaka od desetih točk, ki so na kratko obravnavane zgoraj, zlahka zaslužila samostojen članek, je bil cilj tega članka pomagati razvijalcem ugnezdenih sistemov opredeliti nekatere ključne dejavnike, ki jih morajo upoštevati, preden se lotijo Edge ML projekta. Če na začetku skrbno preučimo vsako od teh vprašanj, bi moralo biti mogoče oblikovati strategijo, ki bo ustvarila optimizirane rešitve, ki izpolnjujejo cilje glede velikosti, moči, stroškov in zmogljivosti, hkrati pa zmanjšuje tveganje projekta, zmanjšuje število ponovnih različic in skrajšuje celoten čas uvajanja na trg.
ABI Research Edge ML Enablement: Poročilo o analizi uporabe razvojnih platform, orodij in rešitev, junij 2022.
O avtorju
Yann LeFaou je pomočnik direktorja v Microchipovi poslovni enoti za dotik in geste. V tej vlogi vodi ekipo, ki razvija kapacitivne tehnologije za dotik, in tudi pobudo podjetja za strojno učenje (ML) za mikrokontrolerje in mikroprocesorje. V podjetju Microchip je opravljal vrsto zaporednih tehničnih in trženjskih funkcij, med drugim je vodil globalne trženjske dejavnosti podjetja na področju kapacitivnega dotika, vmesnika človek-stroj in tehnologije za gospodinjske aparate. LeFaou je diplomiral na univerzi ESME Sudria v Franciji.
Opomba: Ime in logotip Microchip sta registrirani blagovni znamki podjetja Microchip Technology Incorporated v ZDA in drugih državah. Vse druge blagovne znamke, ki so morda tu omenjene, so last njihovih podjetij.
{kind=link}