Hackster Inc.
Marsikdo, ki bo bral te vrstice, se bo verjetno namuznil ob naslovu. Saj smrčanja ni potrebno detektirati – saj ga vendar še predobro slišimo v bližini nekoga, ki smrči!
Točno to – torej zakaj detektirati smrčanje? Odgovor na to je enostaven: če spimo sami brez sostanovalcev, je pa vendarle dobro, da nam neka naprava zazna, ali smo ponoči smrčali ali ne.
Ta naprava na robu učinkovito uporablja model TensorFlow Lite Micro za zaznavanje smrčanja in vas takoj opozori z zvokom.
Po ocenah v ZDA smrči 57 % moških in 40 % žensk, v Združenem kraljestvu pa redno smrči več kot 40 % odraslih. Smrči celo do 27 % otrok. Ti statistični podatki kažejo, da je smrčanje zelo razširjeno, vendar se njegova resnost in posledice za zdravje lahko razlikujejo. Smrčanje je lahko rahlo, občasno in brez skrbi, lahko pa je znak resne osnovne motnje dihanja, povezane s spanjem. Smrčanje je posledica drgetanja in vibriranja tkiv v bližini dihalne poti v zadnjem delu grla. Med spanjem mišice popustijo in zožijo dihalno pot, med vdihom in izdihom pa gibajoči se zrak povzroči, da tkivo drsi in povzroča zvoke.
Ta vsebina je samo za naročnike
Obstruktivna apneja med spanjem je motnja dihanja, pri kateri se dihalne poti med spanjem zamašijo ali sesedejo, kar povzroča ponavljajoče se prekinitve dihanja. Smrčanje je eden najpogostejših simptomov obstruktivne apneje v spanju. Večina ljudi, ki smrči, se tega ne zaveda, razen če jim tega ne pove kdo drug, kar je eden od razlogov, zakaj je apnea v spanju premalo diagnosticirana. V tem projektu sem izdelal dokaz koncepta neinvazivne naprave na robu, ki potroši malo energije in ki spremlja spanje ter brenči, če smrčite.
Kaj potrebujemo pri tem projektu?:
Nordic Semiconductor Nordic Thingy:53
Zephyr Project Zephyr RTOS
Edge Impulse Studio
Nordic Semiconductor nRF Connect SDK


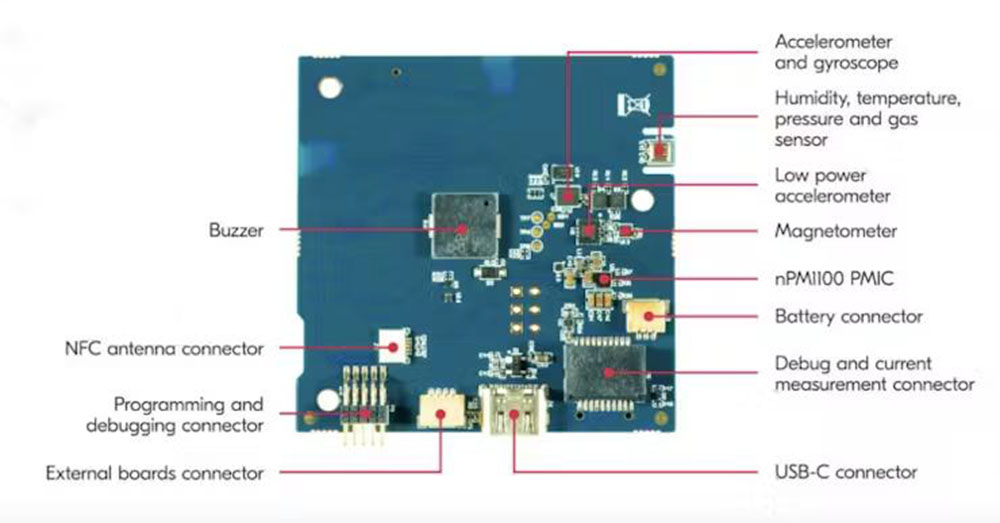
Opis vezja
Uporabljamo Nordic Thingy:53, ki je zgrajen na osnovi nRF5340 SoC. Obdelovalna moč jedra aplikacije (128 MHz) in velikost pomnilnika (512 KB RAM) njegovih dveh procesorjev Arm Cortex-M33 omogočata izvajanje ugnezdenih modelov strojnega učenja neposredno v napravi. Zaradi ohišja s tankim profilom in vgrajene baterije je naprava prenosna in primerna za naš namen.
Ima veliko vgrajenih senzorjev (notranjo razporeditev si oglejte na sliki 2 in sliki 3), vendar bomo v tem projektu uporabljali PDM mikrofon, zvočni signal in RGB LED.
Namestitev razvojnega okolja
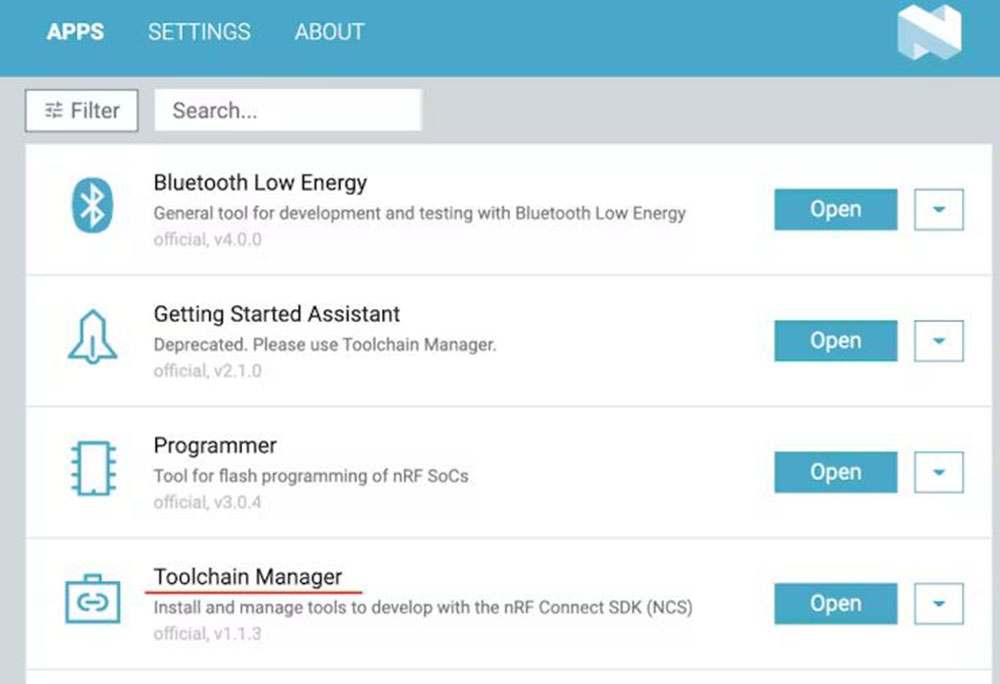
Najprej moramo prenesti nRF connect za namizje iz te spletne strani [1].
nRF Connect for Desktop je medplatformno orodje, ki omogoča testiranje in razvoj z nRF5340. Sledite navodilom za namestitev na zgornji povezavi. Ko je namestitev končana, odprite aplikacijo in kliknite Toolchain Manager ter izberite nRF Connect SDK v2.0.0.
SDK je v sistemu MacOS privzeto nameščen v imeniku /opt/nordic/ncs. Po namestitvi kliknite Open Terminal, ki odpre terminal ukazne vrstice z vsemi inicializiranimi okoljskimi spremenljivkami, da lahko hitro začnete z razvojem.
Za generiranje funkcij ter ustvarjanje in usposabljanje modelov TensorFlow Lite uporabljamo Edge Impulse Studio [2]. Za začetek se moramo prijaviti v brezplačen račun na spletnem mestu https://studio.edgeimpulse.com in ustvariti projekt. Za lokalno razvojno delo se uporablja operacijski sistem MacOS.

Zajemanje podatkov
Za prenos smrčanja in drugih naravnih zvokov, ki se lahko pojavijo ponoči, smo uporabili zbirko podatkov Audioset [3], obsežno zbirko podatkov z ročno anotiranimi zvočnimi dogodki. Zbirka Audioset je sestavljena iz razširjene ontologije 632 razredov zvočnih dogodkov in zbirke človeško označenih 10-sekundnih zvočnih posnetkov iz YouTube videoposnetkov. Zvočni posnetki izbranih dogodkov so pridobljeni iz YouTube videoposnetkov in pretvorjeni v datotečni format Waveform Audio (wav) s 16-bitno globino mono kanala pri vzorčni frekvenci 16 kHz. Prenesene so naslednje kategorije, izbrane iz ontologije Audioset [4]. V prvem stolpcu je ID kategorije, v drugem pa oznaka kategorije.
/m/01d3sd Snoring
/m/07yv9 Vehicle
/m/01jt3m Toilet flush
/m/06mb1 Rain
/m/03m9d0z Wind
/m/07c52 Television
/m/06bz3 Radio
/m/028v0c Silence
/m/03vt0 Insect
/m/07qjznl Tick-tock
/m/0bt9lr Dog
/m/01hsr_ Sneeze
/m/01b_21 Cough
/m/07ppn3j Sniff
/m/07pbtc8 Walk, footsteps
/m/02fxyj Humming
/m/07q6cd_ Squeak
/m/0btp2 Traffic noise, roadway noise
/m/09l8g Human Voice
/m/07pggtn Chirp, tweet
/t/dd00002 Baby cry, infant cry
/m/04rlf Music
Zbirke podatkov so razdeljene v dve kategoriji: smrčanje in šum. S filtriranjem uravnoteženega niza podatkov, neuravnoteženega niza podatkov in ocenjevalnega niza podatkov sta ustvarjeni dve datoteki CSV snoring.csv in noise.csv Datoteke CSV, ki vsebujejo naslove URL posnetkov YouTube in druge metapodatke, lahko prenesete tukaj [5].
Spodnja skripta bash (download. sh) se uporablja za prenos videoposnetka in izpis zvoka kot datoteke wav. Pred zagonom spodnjega ukaza namestite youtube-dl [6] in ffmpeg [7].
#
!/bin/bash
SAMPLE_RATE=16000
fetch_youtube_clip(videoID,
startTime, endTime)
fetch_youtube_clip() {
echo “Fetching $1 ($2 to $3)…”
outname=”$1_$2”
if [ -f “${outname}.wav” ]; then
echo “File already exists.”
return
fi
youtube-dl https://youtube.com/watch?v=$1
–quiet –extract-audio –audio-format wav
–output “$outname.%(ext)s”
if [ $? -eq 0 ]; then
yes | ffmpeg -loglevel quiet -i
“./$outname.wav” -ar $SAMPLE_RATE
-ac 1 -ss “$2” -to “$3”
”./${outname}_out.wav”
mv “./${outname}_out.wav”
”./$outname.wav”
else
sleep 1
Za zagon skripte zaženite spodnji ukaz.
$ cat noise.csv | ./download.sh
$ cat snoring.csv | ./download.sh
Zbirke podatkov se prenesejo v Edge Impulse Studio z uporabo Edge Impulse Uploader. Za namestitev orodij Edge Impulse CLI in izvedbo spodnjih ukazov sledite navodilom tukaj [8].
$ edge-impulse-uploader
–category split –label snoring snoring/.wav $ edge-impulse-uploader –category split –label noise noise/.wav
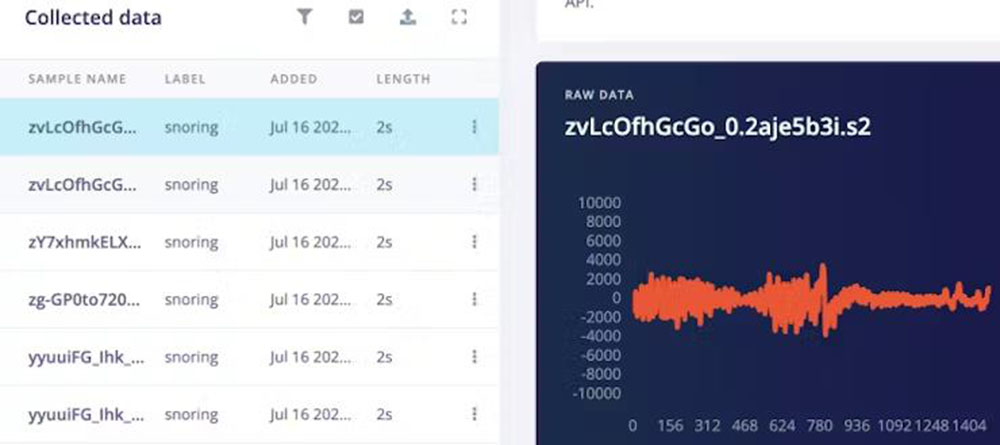
Zgornji ukazi prav tako razdelijo podatkovne nize na učne in testne vzorce. Prenesene podatkovne nize si lahko ogledamo na strani pridobivanja podatkov v programu Edge Impulse Studio.
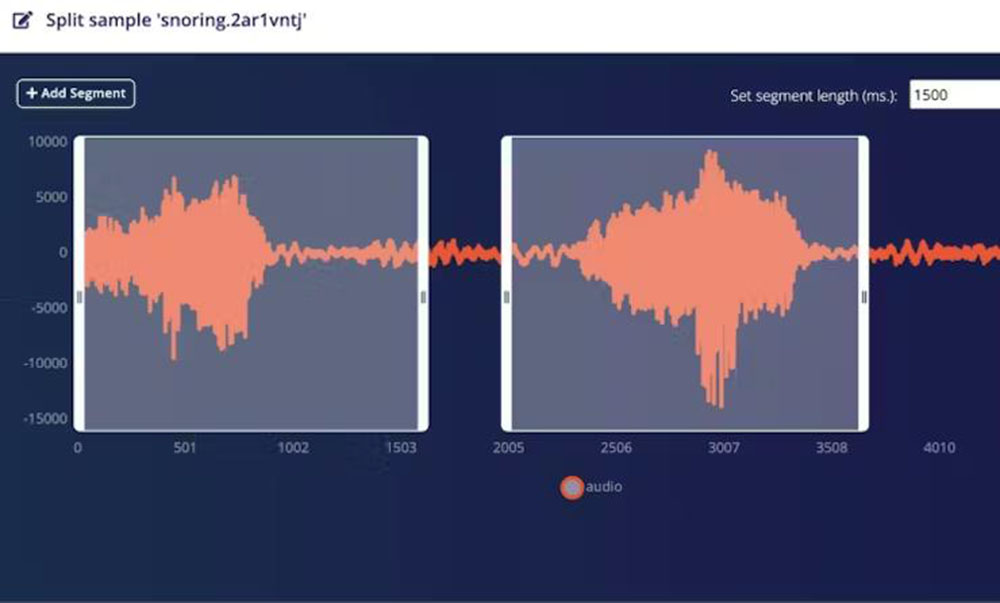
Zvočni posnetki z dogodki smrčanja imajo med več dogodki smrčanja šum v ozadju, ki ga iz posnetkov odstranimo z razdelitvijo segmentov. Zvočni posnetki kategorije šum se uporabijo brez kakršnih koli sprememb.
Razdelitev lahko izvedemo tako, da izberemo vsak vzorec in v spustnem meniju kliknemo na možnost Split sample, vendar je to zamudno in dolgočasno delo. Na srečo obstaja vmesnik API Edge Impulse SDK, ki ga lahko uporabite za avtomatizacijo postopka. Glej program 1.
Program 1:
import json
import requests
import logging
import threading
API_KEY = “ Keys”
projectId = “<Your project ID, can be found
at Edge Impulse dashboard”
headers = {
“Accept”: “application/json”,
“x-api-key”: API_KEY
}
def segment(tid, ids):
for sampleId in ids:
url1 = “https://studio.edgeimpulse.com/v1/api/{}/raw-data/{}/find-segments”.format(projectId, sampleId)
payload1 = {
“shiftSegments”: True,
“segmentLengthMs”: 1500
}
response1 = requests.request(“POST”, url1, json=payload1, headers=headers)
resp1 = json.loads(response1.text)
segments = resp1[“segments”]
if len(segments) == 0:
continue
payload2 = {“segments”: segments}
url2 = “https://studio.edgeimpulse.com/v1/api/{}/raw-data/{}/segment”.format(projectId, sampleId)
response2 = requests.request(“POST”, url2, json=payload2, headers=headers)
logging.info(‘{} {} {}’.format(tid, sampleId, response2.text))
if name == “main”:
format = “%(asctime)s: %(message)s”
logging.basicConfig(format=format, level=logging.INFO,
datefmt=”%H:%M:%S”)
querystring = {“category”:”testing”, “excludeSensors”:”true”}
url = “https://studio.edgeimpulse.com/v1/api/{}/raw-data”.format(projectId)
response = requests.request(“GET”, url, headers=headers, params=querystring)
resp = json.loads(response.text)
id_list = list(map(lambda s: s[“id”], resp[“samples”]))
div = 8
n = int(len(id_list) / div)
threads = list()
for i in range(div):
if i == (div – 1):
ids = id_list[ni: ] else: ids = id_list[ni: n*(i+1)]
x = threading.Thread(target=segment, args=(i, ids))
threads.append(x)
x.start()
for thread in threads:
thread.join()
logging.info(“Finished”)
Trening
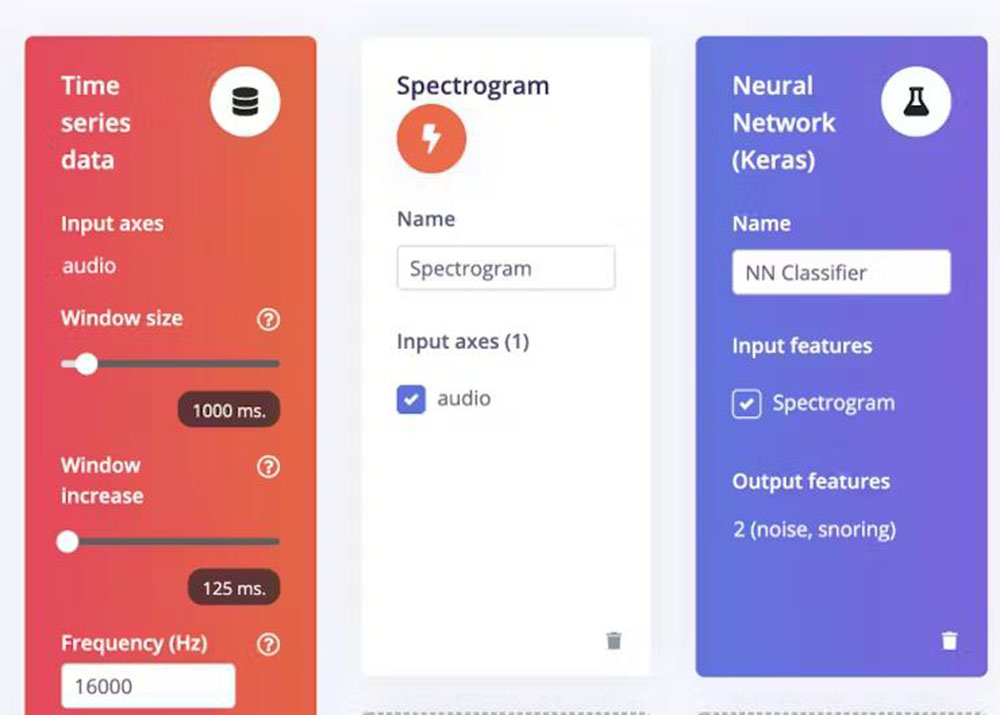
Pojdite na stran Impulse Design > Create Impulse, kliknite na tipko Add a processing block in izberite Spectrogram, ki je vizualni način za predstavitev jakosti ali „glasnosti“ signala v času pri različnih frekvencah, prisotnih v določeni obliki valovanja. Na isti strani kliknite tudi na blok Add a learning in izberite Neural Network (Keras), ki se iz podatkov uči vzorce in jih lahko uporabi za nove podatke. Izbrali smo velikost okna 1000 ms in povečanje okna za 125 ms. Zdaj kliknite tipko Save Impulse.
Zdaj pojdite na stran Impulse Design > Spectrogram in spremenite parametre, kot je prikazano na sliki 10, ter kliknite tipko Save parameters. Izbrali smo dolžino okvirja = 0,02 s, korak okvirja = 0,01538 s, frekvenčne pasove = 128 (velikost FFT) in spodnji nivo šuma = -54 dB. Spodnja meja šuma se uporablja za filtriranje šuma ozadja v spektrogramu. Najprej razdeli okno na več prekrivajočih se okvirjev. Velikost in število okvirjev lahko prilagodite s parametroma Dolžina okvirja in Razmik okvirja. Na primer, pri oknu z velikostjo 1000 ms, dolžini okvirja 20 ms in koraku 15,38 ms bo ustvaril 65 časovnih okvirov. Vsak časovni okvir nato razdelimo na frekvenčne bine z uporabo FFT (hitra Fourierova transformacija) in izračunamo njegov energijski spekter. Število frekvenčnih binov je enako parametru Frekvenčni pasovi, deljenemu z 2 plus 1. Značilnosti, ki jih ustvari blok Spektrogram, so enake številu ustvarjenih časovnih okvirov, pomnoženemu s številom frekvenčnih binov.
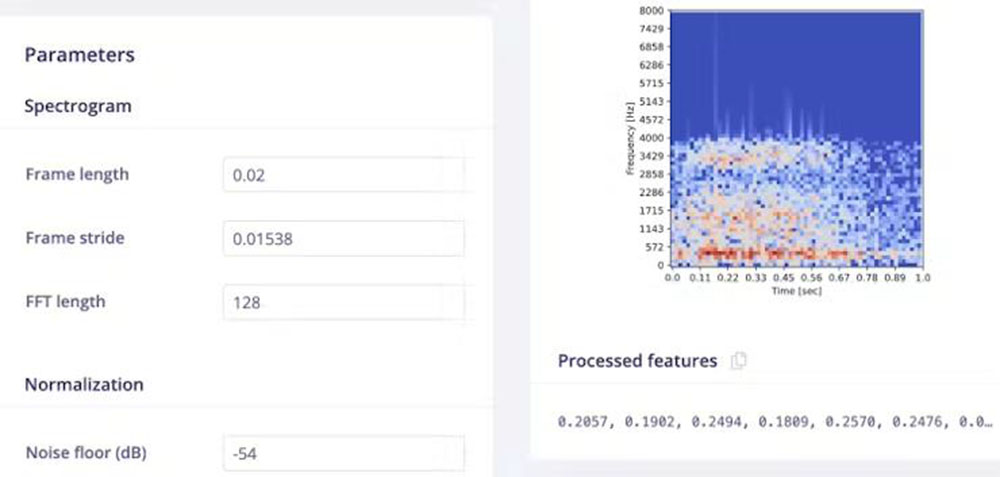
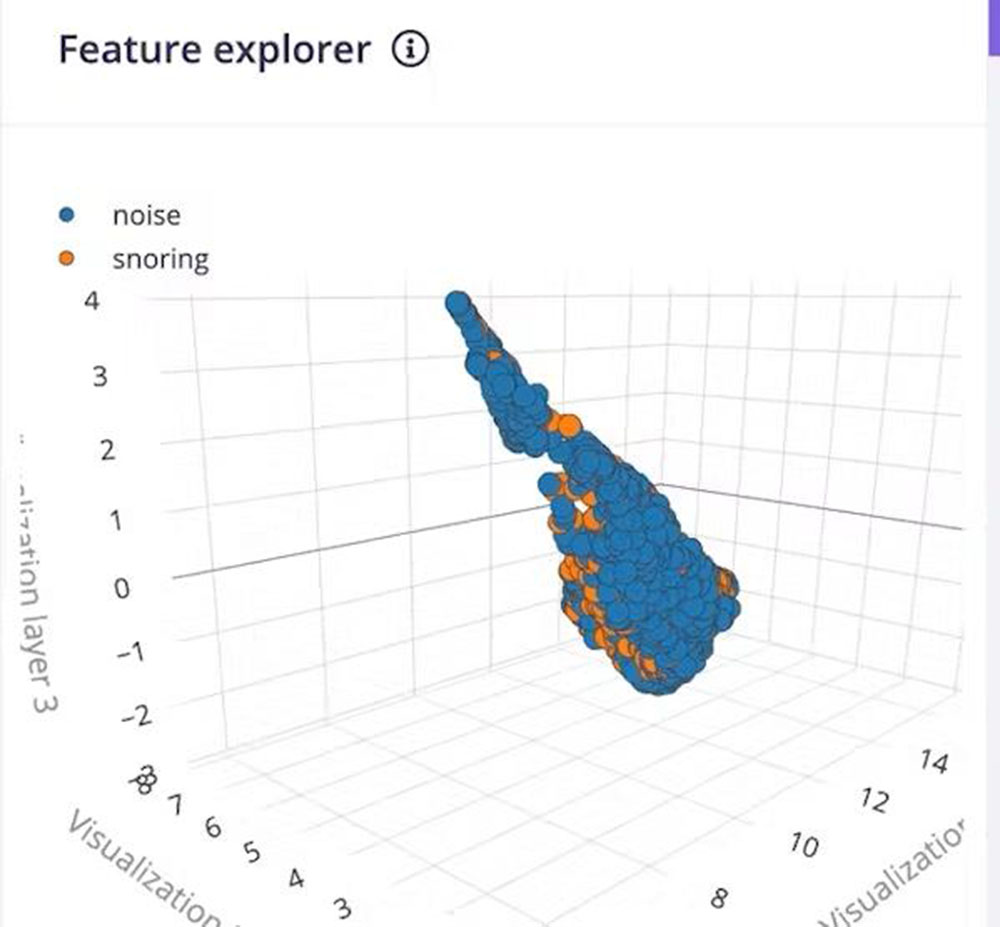
Klik na tipko Save parameters nas preusmeri na drugo stran, kjer moramo klikniti na tipko Generate Feature. Običajno traja nekaj minut, da se generiranje funkcije zaključi. V Raziskovalcu funkcij si lahko ogledamo 3D vizualizacijo ustvarjenih funkcij.
Zdaj pojdite na stran Impulse Design > Classifier in v spustnem meniju izberite Switch to Keras (expert) mode ter določite arhitekturo modela. Na voljo je veliko modelov za klasifikacijo zvoka, ki so že na voljo, vendar imajo veliko število parametrov, zato niso primerni za mikrokontrolerje z 256 kB ali manj pomnilnika. Po številnih poskusih smo ustvarili arhitekturo modela, ki je prikazana spodaj. Glej program 2.
Program 2:
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Reshape, Conv2D, Flatten, ReLU, Dropout, MaxPooling2D, Dense
from tensorflow.keras.optimizers.schedules import InverseTimeDecay
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.layers.experimental import preprocessing
sys.path.append(‘./resources/libraries’)
import ei_tensorflow.training
channels = 1
columns = 65
rows = int(input_length / (columns * channels))
norm_layer = preprocessing.Normalization()
norm_layer.adapt(train_dataset.map(lambda x, _: x))
model architecture
model = Sequential()
model.add(Reshape((rows, columns, channels), input_shape=(input_length, )))
model.add(preprocessing.Resizing(24, 24, interpolation=’nearest’))
model.add(norm_layer)
model.add(Conv2D(16, kernel_size=3))
model.add(ReLU(6.0))
model.add(Conv2D(32, kernel_size=3))
model.add(ReLU(6.0))
model.add(MaxPooling2D(pool_size=2, strides=2, padding=’same’))
model.add(Dropout(0.7))
model.add(Flatten())
model.add(Dense(64))
model.add(ReLU(6.0))
model.add(Dense(32))
model.add(ReLU(6.0))
model.add(Dense(classes, activation=’softmax’, name=’y_pred’))
BATCH_SIZE = 64
lr_schedule = InverseTimeDecay(
0.0005,
decay_steps=train_sample_count//BATCH_SIZE*15,
decay_rate=1,
staircase=False)
def get_optimizer():
return Adam(lr_schedule)
EPOCHS = 70
train_dataset = train_dataset.batch(BATCH_SIZE, drop_remainder=False)
validation_dataset = validation_dataset.batch(BATCH_SIZE, drop_remainder=False)
callbacks.append(BatchLoggerCallback(BATCH_SIZE, train_sample_count, EPOCHS))
train the neural network
model.compile(loss=’categorical_crossentropy’, optimizer=get_optimizer()
, metrics=[‘accuracy’])
model.fit(train_dataset, epochs=EPOCHS, validation_data=validation_dataset
, verbose=2, callbacks=callbacks)
Pri opredelitvi arhitekture modela smo jo po najboljših močeh poskušali optimizirati za primer uporabe TinyML. Ker bi 64×65 enokanalnih funkcij spektrograma vsebovalo veliko število parametrov za učenje, sestavljeni model pa se ne bi prilegal razpoložljivemu pomnilniku RAM mikrokontrolerja, smo spremenili velikost spektrograma na 24×24, kar je najboljša rešitev za razmerje med velikostjo in natančnostjo modela. Uporabili smo tudi aktivacijo z omejenim obsegom (ReLU6), ker ReLU6 omejuje izhod na [0, 6] in kvantizacija po usposabljanju ne poslabša natančnosti. Povzetek modela je podan spodaj. Glej program 3.
Program 3:
Model: “sequential”
Layer (type) Output Shape Param #
reshape (Reshape) (None, 64, 65, 1) 0
resizing (Resizing) (None, 24, 24, 1) 0
normalization (Normalization (None, 24, 24, 1) 3
conv2d (Conv2D) (None, 22, 22, 16) 160
re_lu (ReLU) (None, 22, 22, 16) 0
conv2d_1 (Conv2D) (None, 20, 20, 32) 4640
re_lu_1 (ReLU) (None, 20, 20, 32) 0
max_pooling2d (MaxPooling2D) (None, 10, 10, 32) 0
dropout (Dropout) (None, 10, 10, 32) 0
flatten (Flatten) (None, 3200) 0
dense (Dense) (None, 64) 204864
re_lu_2 (ReLU) (None, 64) 0
dense_1 (Dense) (None, 32) 2080
re_lu_3 (ReLU) (None, 32) 0
y_pred (Dense) (None, 2) 66
Total params: 211,813
Trainable params: 211,810
Non-trainable params: 3
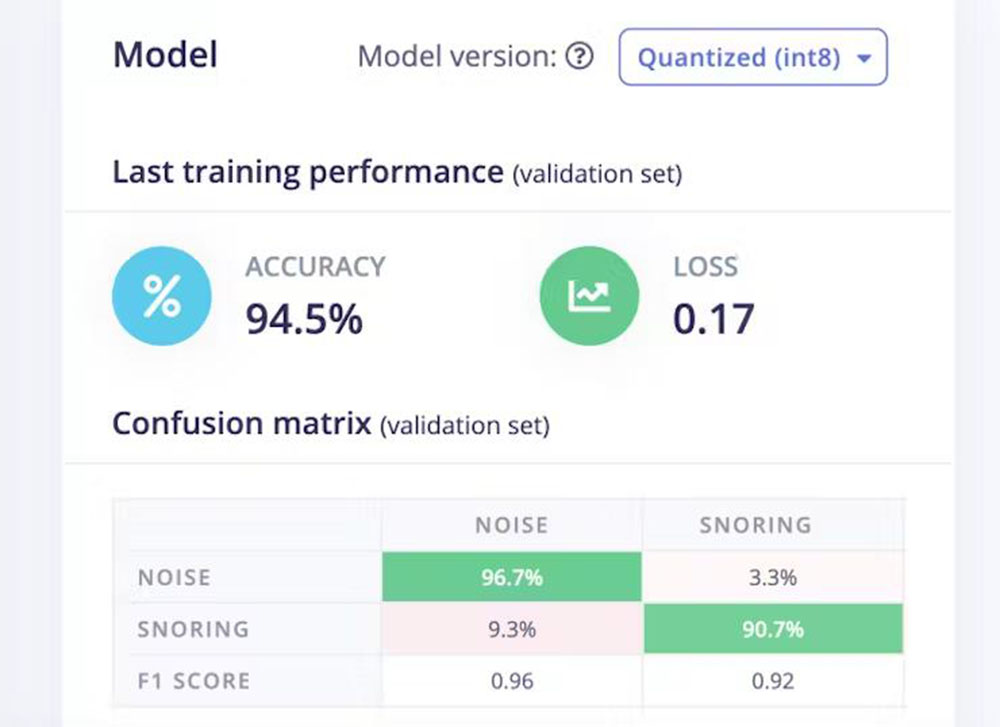
Zdaj kliknite tipko Start Training in počakajte približno eno uro, da se usposabljanje konča. Na sliki 12 si lahko ogledamo rezultate usposabljanja in matriko napak. Model ima 94,5-odstotno natančnost.
Namestitev
Ker bomo model namestili v Nordic Thingy:53, bomo na strani Deployment izbrali možnost Create Library > C++ library. Za možnost Select optimization bomo izbrali možnost Enable EON Compiler, ki zmanjša porabo pomnilnika modela.
Prav tako bomo izbrali kvantizirani model (Int8). Zdaj kliknite tipko Build in v nekaj sekundah se bo sveženj knjižnice prenesel v lokalni računalnik. Za sklicevanje smo ustvarili nov projekt Zephyr, ki si večino kode izposodi iz projekta ugnezdene programske opreme Edge Impulse Thingy:53 in ga lahko klonirate iz repozitorija GitHub.
$ git clone
https://github.com/metanav/thingy53_
snoring_detection.gitZdaj razpakirajte preneseni paket knjižnic in kopirajte naslednje imenike v imenik ei-model v korenskem imeniku projekta.
Edge-impulse-sdk
model-parametri
tflite-model

Obstaja več načinov za vstavljanje ugnezdene programske opreme v napravo Nordic Thingy:53. Mi smo uporabili J-Link Edu Mini, zunanjo sondo za razhroščevanje, da smo ugnezdeno programsko opremo programirali po spodnjih korakih:
Odprite pokrov priključka na strani naprave Nordic Thingy:53 (glejte sliko 13).
S kablom JTAG povežite Nordic Thingy:53 z izhodnim priključkom za odpravljanje napak na 10-pinski zunanji sondi za odpravljanje napak.
Vklopite napravo Nordic Thingy:53; prestavite stikalo za napajanje SW1 v položaj ON.
Zunanjo sondo za odpravljanje napak povežite z računalnikom s kablom micro-USB.
Po nastavitvi strojne opreme zaženite spodnji ukaz.
$ west flashKo se programiranje uspešno zaključi, se aplikacija začne izvajati.
Demonstracijski primer sklepanja
Aplikacija vzorči 1000 ms zvočnih zapisov z vzorčno frekvenco 16 kHz iz vgrajenega PDM mikrofona in neprekinjeno izvaja sklepanje. Ko zazna zvok smrčanja, se vgrajena RGB LED obarva zeleno, zvočni signal pa začne piskati. Da bi se izognili lažno pozitivnim rezultatom, se zadnjih 10 napovedi shrani v krožni predpomnilnik za sprejemanje odločitev. Dnevnike sklepanja je mogoče spremljati prek serijske povezave USB s hitrostjo 115200 baudov. Hitrost sklepanja je pod 100 ms na vzorec.
Predictions (DSP: 18 ms.
, Classification: 66 ms., Anomaly: 0 ms.):
noise: [0.88]
snoring: [0.12]
Zaključek
Ta projekt predstavlja rešitev za resnični problem, ki se sicer na prvi pogled zdi smešen, vendar zahteva skrbno obravnavo. Gre za napravo, ki je priročna in preprosta za uporabo in ki spoštuje zasebnost uporabnikov, saj izvaja sklepanje na robu. Čeprav model TensorFlow Lite Micro deluje precej dobro, je še vedno dovolj prostora za izboljšave. Z večjo količino urejenih učnih podatkov lahko model postane natančnejši in robustnejši. Ta projekt tudi prikazuje, da je mogoče preprosto nevronsko mrežo uporabiti za reševanje zapletenih problemov, če je obdelava signalov pravilno izvedena in se izvaja na napravah z majhno močjo in omejenimi viri, kot je Nordic Thingy:53.
Viri:
1: https://www.nordicsemi.com/Software-and-tools/Development-Tools/nRF-Connect-for-desktop/Download
2: https://studio.edgeimpulse.com/
3: https://research.google.com/audioset/
4: https://github.com/audioset/ontology/blob/master/ontology.json
- https://research.google.com/audioset/download.html
6: https://github.com/ytdl-org/youtube-dl
7: http://ffmpeg.org/download.html
8: https://docs.edgeimpulse.com/docs/cli-installation
Povzeto po:
https://tinyurl.com/48m6fac3
{kind=link}